
Overview
DataBlend supports a variety of collectors which receive information from SFTP locations. Users can conveniently receive information from a local or remote SFTP. Excel (.xlsx), delimited (e.g. csv), Flat, and JSON files can be uploaded directly to a DataBlend stream. How the data is processed depends on the schema type and upload settings.
For more information about streams and their relationship to schemas and data sources, see Data Sources, Schemas, and Streams.
Configuration
| Field | Required / Optional | Comments |
|---|---|---|
| Name | Required | Descriptive free-text name for the collector. |
| Data Source | Required | Select a pre-configured data source from the drop-down or click Create New to create a new data source. |
| Credential | Required | Select a pre-configured credential from the drop-down. |
| Path | Required | Enter an exact filename or a subdirectory and filename. Do not start with /. |
| Use Regular Expression | Optional | If false, the directory/filename in Path is used exactly as entered.If true, the value of Path is treated as a regular expression:.*\.csv — matches any file ending in .csv.*\.xlsx — matches any file ending in .xlsx/GC.*\.csv — matches any file starting with GC and ending in .csv |
| Match Limit Only shown when Use Regular Expression is ON |
Optional | Limits the number of files collected per run when Use Regular Expression is enabled. Enter 0 for no limit — all files matching the Path expression will be collected.Enter any positive integer to collect up to that number of matching files per run. For example, set to 1 if a workflow is triggered by file drops and you want to process one file at a time. To ensure additional files dropped at the same time are not skipped, configure the workflow to Run in Sequence under its Advanced tab. |
| File Definition | Required | Specifies how DataBlend should parse the collected file. Select from the drop-down: Delimited - For comma-separated or other character-delimited files (e.g. CSV, TSV, pipe-delimited). A Delimiter field will appear; if left blank, comma is assumed. For tab-delimited files enter /t or TAB.Excel - For .xlsx or .xls files. Schema name must match the tab name in the Excel file, or use the Use Sheet Index toggle to collect by tab position (0 = first tab, 1 = second tab, etc.).Flat - For fixed-width files where columns are defined by character position rather than a delimiter. JSON - For JSON-formatted files. An Is Array field will appear if the JSON contains an array. Raw - Collects the file as raw, unprocessed content. |
| Skip Rows | Optional | Enter the number of rows to skip from the top of the file before DataBlend begins reading data. For example, enter 1 to skip a single header row, or 3 to skip three rows. A single whole number is expected — do not enter a range (e.g. 1-3) or a list (e.g. 1, 2, 3). |
| Archive Option | Optional | Controls what happens to the source file after collection. None — File is left in place (default). Copy — File is copied to the Archive Path; the original remains in place. Move — File is moved to the Archive Path; the original is removed. Delete — File is deleted after collection. |
| Archive Path Only shown when Archive Option is Copy or Move |
Required when Archive Option is Copy or Move | The path where archived files will be stored. Important: It is strongly recommended to include a timestamp in the archive filename. If a file with the same name already exists in the Archive Path, the move or copy will fail and the original file will be collected again on the next run. DataBlend automatically appends a timestamp (including seconds) when one is not present. To add one manually, use a timestamp variable in the path, for example: /archive/invoices_{timestamp}.csv |
| Delete Files When Finished | Optional | If true, any file(s) processed by the collection are deleted when the collection completes. Files processed by previous collections are not affected. |
| Use Bookmark | Optional | When enabled, this value is updated each time the collection runs. Only files uploaded after the bookmarked time will be processed, preventing double-processing of files that were not deleted. To reprocess files, clear the bookmark. |
How to upload a file
To begin a file upload, browse to the schema that you wish to update.
A file can only be uploaded to an open stream from the stream details page.
Select a Stream
Look at the stream section for any open streams. (An open stream will not have a Closed date.)

If there is an existing open stream, decide if you want to upload to the existing stream or if you wish to create a new one.
|
If Schema Type Is… |
… Then Upload to Existing Open Stream Will… |
|---|---|
|
Default |
Add contents of file to existing contents of stream. |
|
Realtime |
Add contents of file to existing contents of stream. |
|
Single-file |
Overwrite existing contents of stream with contents of the file. |
If you do not wish to add the contents of the file to an existing stream, then close the open stream and create a new one.
If there is not an existing open stream, create a new one.
Upload a File
A stream which can be written to will have a file upload box.
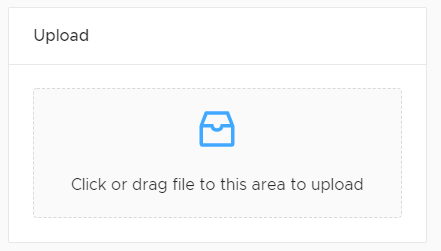
Drop the file on the upload box (or use the file selector to find it) and the upload settings box will open.
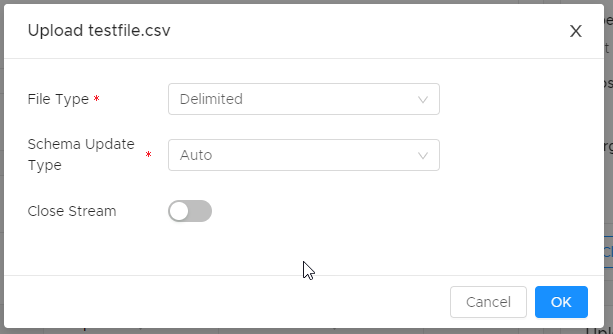
|
Option |
Description |
|---|---|
|
File Type |
DataBlend will identify the file type where possible, but this setting can be changed if necessary. |
|
Schema Update Type |
Add New Columns (formerly Add Only): Existing schema columns are preserved regardless of whether they exist in the first record collected. New columns identified in the first record collected are added to the schema. If the collection returns no records, the existing schema is unchanged. Recreate Columns (formerly Auto): Default. Schema is recreated from the first record collected. If the collection returns no records, the existing schema is unchanged. Preserve Columns (formerly Manual): No changes are made to the schema during collection. If the schema is changed by the file upload, data in previous streams may no longer be available. (Columns may “go missing”.) When in doubt, set to Add New Columns.
|
|
Leave set to false if:
Set to true if:
|
Archive
File Collection is now available for archive. If the archiving is not preferred, please select none from the drop-down menu. Copy will copy the file to Archive Path. Move will move the file data to a new path. Delete will delete file data upon collection.
Important: When Copy or Move is selected as Archive Option the Archive Path is required. DataBlend recommends including a timestamp in the Archive Path filename to prevent naming conflicts. If a file with the same name already exists in the archive folder, the file will not be moved and may be collected again on the next run.
Bookmarks
Bookmarks can be used on certain collectors to set a dynamic value each time the collector runs. A field from the collector source will need to be selected to be associated with the Bookmark function. For example, ‘WHENMODIFIED’ is a field in the Sage Intacct GL Detail object that can be used as a Bookmark:

Once the Bookmark Field is set, every collection will save the value based on the latest run time. In the example above, the Bookmark is stored as a 'WHENMODIFIED' date of '05/17/2022 04:22:10'. The next time the Collector runs, it will only pull values with a different value, and then will update the Current Value field dynamically.
Other Notes about Bookmarks:
-
Most commonly set as date fields, the Bookmark Field can also be a non-date field.
-
Filters on the collector can still be applied, so even though a Bookmark may be set, if a filter is present it will still only collect data with both the Bookmark value and filters in mind.
-
-
To accomplish this consolidation in the query, your FROM section will need to leverage ‘All Streams’. This will also carry a risk that if the bookmark’s ‘Current Value’ is cleared or the bookmark is removed, the same data can be included into a new stream and therefore overstate the dataset that is being used in the query. It is important to be mindful of which collectors and queries are relying on the bookmark functionality and avoid modifying the bookmark while in use. To reset the bookmarked data, make sure to clear the ‘Current Value’ and also purge all streams or create a new Schema so that you’re starting from an empty dataset.
Data gets collected into a new stream even when Bookmarks are present, the data does not automatically consolidate into one stream. Consolidation would need to be done in a query.
-
Details
-20211028-153128.png?width=481&height=443&name=Screenshot%20(139)-20211028-153128.png)
The details section documents who the Collector was created and updated by and the corresponding times. This allows for easy tracking of multiple Collectors.
Latest Collection
-20211028-153206%20(1).png?width=499&height=383&name=Screenshot%20(138)-20211028-153206%20(1).png)
The latest collection section documents the state of the collector, created time, and the status of the query. States include complete and error.
Collections
-20211028-153229%20(1).png?width=670&height=221&name=Screenshot%20(137)-20211028-153229%20(1).png)
The Collections section documents when the Collector was created, started, completed and the total amount of data scanned. The status includes information regarding the state of the Collector. This allows for easy tracking of multiple collections.
Upload History

File uploads will be run as jobs in the background. The number of records processed or any error encountered will be displayed in the Uploads history table.